Introduction
This article discusses some unknown feature of SQL LIKE operator e.g. using set, range, exclusion and escape sequences in where expression with SQL LIKE operator.
Background
While working in any .net and other programming languages, we are used to using regular expression for search a pattern in a text. When it comes to SQL we find ourselves struggling to write filter expression. There are some features of SQL LIKE operator which might help you writing better filter expressions.
Discussion
There are following features which I would discuss in this article.
1. Range of values
2. List of values
3. Exclusion of a list or range of values
4. Escape Sequence
Range Of Values:
Like in regular expression if we want to search based on a sequence, we use bracket to specify the sequence. e.g. [1-5] means all digits between 1 and 5 inclusive or [a-z] means all characters between 'a' and 'z'. Do you know that the same expressions can be used in SQL Server like operator.
SELECT * FROM TBL_MYTABLE WHERE MYCOL LIKE '[a-r]%'
In the above examples, we have selected all rows for which MYCOL starts with any character lying between 'a' and 'r'.
List Of Values:
Again like in Regular expression, if we want to search for a list of values, we can search using square brackets. In this example we want to select all those rows which has 'a','e','i','o' or 'u' as data in MYCOL column. The query is very easy.
SELECT * FROM TBL_MYTABLE WHERE MYCOL LIKE '[aeiou]'
Exclusion Of a List or Range of Values:
This is used when we want to exclude any set of character or range of character. In this example, we are excluding those rows for which MYCOL does not start with any character in the range of characters from 'a' to 'r'.
SELECT * FROM TBL_MYTABLE WHERE MYCOL LIKE '[^a-r]%'
We can also exclude a list of characters. Like in the example below, we are excluding all rows where value of MYCOL start with any of 'a','e','i','o' or 'u':
SELECT * FROM TBL_MYTABLE WHERE MYCOL LIKE '[^aeiou]%'
Escape sequence:
What if % is part of your data you want to filter based on some filter criteria in SQL through LIKE operator. The obvious answer is use escape sequence so that we could specify to the runtime that we are expecting % as data. But do you know how we specify escape sequence in SQL Like operator.
You can do that using escape operator after the filter criteria. Let us see an example in which '%' and '_' can be part of our data. We want to select only those rows which contain these characters as data.
SELECT * FROM TBL_MyTable where MyCol LIKE '%[\%\_]%' {ESCAPE '\'}
It must be remembered that using more than one character as escape sequence results in Error.
Showing posts with label T-SQL. Show all posts
Showing posts with label T-SQL. Show all posts
Saturday, March 7, 2009
Saturday, December 6, 2008
T-SQL and MINUS operator
SELECT statement is an integral part of SQL. The result obtained by a SELECT statement has always been referred as SET. In this way, it should support all SET operations.
What I was amazed to know that T-SQL does not support MINUS operator. MINUS is one of the SET operations. There are definitely some workarounds that you can think of. But all of them asks you to change the natural way of getting the result set using some TECHNIQUES which I don't like.
What do you say about this? Do you want to support this or you have some alternate thoughts about this?
What I was amazed to know that T-SQL does not support MINUS operator. MINUS is one of the SET operations. There are definitely some workarounds that you can think of. But all of them asks you to change the natural way of getting the result set using some TECHNIQUES which I don't like.
What do you say about this? Do you want to support this or you have some alternate thoughts about this?
Saturday, September 13, 2008
Grouping Set (SQL Server 2008)
People cannot help appreciating GROUP BY clause whenever they have to get a DISTINCT from any result set. Additionally whenever any aggregate function is required GROUP BY clause is the only solution. There has always been requirement get these aggregate function based on different set of columns in the same result set. It is also safe to use this feature as this is an ISO standard.
Though the same result could be achieved earlier but we have to write different queries and would have to combine them using UNION operator. The result set returned by GROUPING SET is the union of the aggregates based on the columns specified in each set in the Grouping set.
To understand it completely first we create a table tbl_Employee.

Now we populate table with some the following rows:

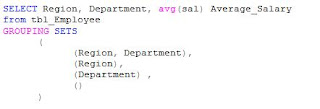
After populating with the rows, we select some rows using Grouping Sets.
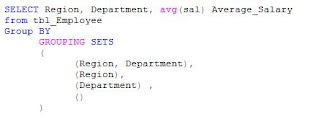
The result of this statement is as follows:
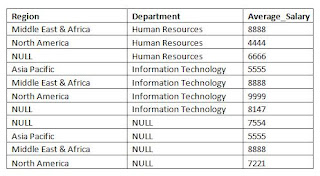
You can see that the result set contains rows grouping by each set in the specified Grouping Sets. You can see the average salary of employees for each region and department. You can also appreciate the average salary of employees for the organization (NULL for both Region and Department). This was the result of empty Grouping Set i.e. ().
Before 2008, if you had to get the same result set, following query had to be written:
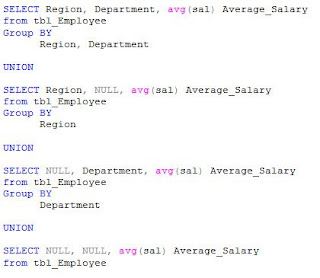
By looking at the above query, you can appreciate the ease provided by Grouping Set to the developer.
CUBE Sub Clause for Grouping
This is used to return power ‘n’ to 2 for ‘n’ elements.

The above query is equivalent to the following query:
ROLLUP operator for Grouping
This is used to return ‘n+1’ grouping sets for ‘n’ elements in the hierarchy scenario.

This is equivalent to the following query:

Though the same result could be achieved earlier but we have to write different queries and would have to combine them using UNION operator. The result set returned by GROUPING SET is the union of the aggregates based on the columns specified in each set in the Grouping set.
To understand it completely first we create a table tbl_Employee.

Now we populate table with some the following rows:

After populating with the rows, we select some rows using Grouping Sets.

The result of this statement is as follows:

You can see that the result set contains rows grouping by each set in the specified Grouping Sets. You can see the average salary of employees for each region and department. You can also appreciate the average salary of employees for the organization (NULL for both Region and Department). This was the result of empty Grouping Set i.e. ().
Before 2008, if you had to get the same result set, following query had to be written:

By looking at the above query, you can appreciate the ease provided by Grouping Set to the developer.
CUBE Sub Clause for Grouping
This is used to return power ‘n’ to 2 for ‘n’ elements.

The above query is equivalent to the following query:

ROLLUP operator for Grouping
This is used to return ‘n+1’ grouping sets for ‘n’ elements in the hierarchy scenario.

This is equivalent to the following query:

Friday, September 5, 2008
Resource Governor (SQL Server 2008)
I have written an article about Resource Governor. A feature introduced in SQL Server 2008.
Click: SQL Server 2008 Resource Governor
Click: SQL Server 2008 Resource Governor
Thursday, September 4, 2008
T-SQL Debugger (SQL Server 2008)
Gone are the days in which you could not debug your code in SQL Server Management Studio. The only option that SQL Server developers had was to add their stored procedures and other programming objects into Visual Studio project and debugging their code from the Visual Studio IDE. With SQL Server 2008, Microsoft has included full-fledged debugger in SQL Server Management Studio.
Like other debugging tools, we can add break-points in our T-SQL code. Pressing F9 would add the break-point as generally is the standard in other Microsoft tools.
There are different windows available for debugging the code. The windows include:
1. 'Local'
2. 'Call Stack'
3. 'Output'
4. 'Command Window'
5. 'Threads'
6. 'BreakPoints'
7. 'Watch'
You can 'Step Into', 'Step Out' or 'Step Over' the code. There are same short-cut keys available as in other Microsoft tools.
The 'Quick Watch' feature is also available. With this feature, you can evaluate any expression evaluated under the environment of execution of current code.
You can also toggle, delete or disable breakpoints.
Enjoy this feature!
Like other debugging tools, we can add break-points in our T-SQL code. Pressing F9 would add the break-point as generally is the standard in other Microsoft tools.
There are different windows available for debugging the code. The windows include:
1. 'Local'
2. 'Call Stack'
3. 'Output'
4. 'Command Window'
5. 'Threads'
6. 'BreakPoints'
7. 'Watch'
You can 'Step Into', 'Step Out' or 'Step Over' the code. There are same short-cut keys available as in other Microsoft tools.
The 'Quick Watch' feature is also available. With this feature, you can evaluate any expression evaluated under the environment of execution of current code.

You can also toggle, delete or disable breakpoints.
Enjoy this feature!
Wednesday, August 20, 2008
IN Clause (SQL Server)
Today I want to discuss one thing about IN clause in SQL Server.
SELECT * from
tblcustomer
WHERE
(ID, Name) in (
select CustomerID, CustomerName from tblCustomerOrders
)
In the above statement, we wanted to list the details of customers who have submitted some orders. When you run this statement in SQL Server (with the tables tblCustomer and tblCustomerOrders already created), an error is generated about this. The real reason is that SQL Server does not support more than one parameters in the IN clause.
SELECT * from
tblcustomer
WHERE
(ID, Name) in (
select CustomerID, CustomerName from tblCustomerOrders
)
In the above statement, we wanted to list the details of customers who have submitted some orders. When you run this statement in SQL Server (with the tables tblCustomer and tblCustomerOrders already created), an error is generated about this. The real reason is that SQL Server does not support more than one parameters in the IN clause.
Monday, August 18, 2008
Compound Assignment Operators (SQL Server 2008)
Like other .net programming languages compound assignment operators are introduced in SQL Server 2008. If you want to do any basic arithmatic operation (+, -, *, /, %) with any variable and simultaneously assign it to the variable then this proves to be easier in implementation.
DECLARE @MyIntVar INT = 4
SET @myINTVar += 2
SELECT @myINTVar
DECLARE @MyIntVar INT = 4
SET @myINTVar += 2
SELECT @myINTVar
Inline Initialization of Variables in SQL Server 2008
Before 2008, variables could only be assigned with a value using SELECT or SET statements. There was no way to assign any value to a variable at the time when it is declared. With 2008, Microsoft has removed this shortcoming and introduced this feature. This inline initialization can be done using literal or any function.
E.g.
DECLARE @myINTVar INT = 3
DECLARE @myVARCHARVar VARCHAR = LEFT('Shujaat',1)
SELECT @myINTVar, @myVARCHARVar
E.g.
DECLARE @myINTVar INT = 3
DECLARE @myVARCHARVar VARCHAR = LEFT('Shujaat',1)
SELECT @myINTVar, @myVARCHARVar
Table Valued Constructors using VALUES clause
From Today onwards, I am starting a series of Article concerning new T-SQL features introduced in SQL Server 2008. The first article of this series is as under:
Before 2008, when more than one rows were to be inserted using INSERT statement, then more than one INSERT statements were required. But with SQL Server 2008, it is not necessary because only one INSERT statement would do the work. Consider a table with three columns ID, Name and Address.
CREATE TABLE TblCustomer
(
ID int PRIMARY KEY IDENTITY,
Name VARCHAR(30),
Address varchar(45)
)
The single INSERT statement is as under:
INSERT INTO TblCustomer(Name, [Address] )
VALUES ('Shujaat', 'New Jersey'),
('Siddiqi', 'California'),
('Shahbaz', 'Los Angeles')
This can also be used for bulk insert requirements because of its atomic nature. After creating this statement in you .net code, you may pass this statement to the database. This INSERT statement is an atomic operation so there aren’t three statements being executed but only single statements in executed in the database.
This constructor may also be used for SELECT and MERGE statements. The example is as follows:
SELECT VendorID, VendorName
FROM
(
VALUES(1, 'Shujaat'),
(2, 'Siddiqi')
) AS Vendor(VendorID, VendorName)
Before 2008, when more than one rows were to be inserted using INSERT statement, then more than one INSERT statements were required. But with SQL Server 2008, it is not necessary because only one INSERT statement would do the work. Consider a table with three columns ID, Name and Address.
CREATE TABLE TblCustomer
(
ID int PRIMARY KEY IDENTITY,
Name VARCHAR(30),
Address varchar(45)
)
The single INSERT statement is as under:
INSERT INTO TblCustomer(Name, [Address] )
VALUES ('Shujaat', 'New Jersey'),
('Siddiqi', 'California'),
('Shahbaz', 'Los Angeles')
This can also be used for bulk insert requirements because of its atomic nature. After creating this statement in you .net code, you may pass this statement to the database. This INSERT statement is an atomic operation so there aren’t three statements being executed but only single statements in executed in the database.
This constructor may also be used for SELECT and MERGE statements. The example is as follows:
SELECT VendorID, VendorName
FROM
(
VALUES(1, 'Shujaat'),
(2, 'Siddiqi')
) AS Vendor(VendorID, VendorName)
Friday, August 1, 2008
Joining with a result set returned from a UDF (CROSS AND OUTER APPLY)
I have a function which returns a result set. Now I need to join the result
set with a table in a SELECT query. How can I do that?
This question led me to a feature of T-SQL which is APPLY. This comes in
two flavors. They are as follows:
1. Cross Apply
2. Outer Apply
Both are used to join with the result set returned by a function. Cross
apply works like an INNER JOIN and OUTER apply works like LEFT OUTER JOIN.
set with a table in a SELECT query. How can I do that?
This question led me to a feature of T-SQL which is APPLY. This comes in
two flavors. They are as follows:
1. Cross Apply
2. Outer Apply
Both are used to join with the result set returned by a function. Cross
apply works like an INNER JOIN and OUTER apply works like LEFT OUTER JOIN.
Wednesday, April 30, 2008
Operation causing trigger to fire
Oracle has two options for DML triggers on a table. 1- They can be set up to fire for each row modified. 2- The can be set for each statement executed e.g. Insert, update, delete. I learnt an awkward thing about SQL server 2005 DML trigger today that it can not be set for execution for each row being inserted, deleted or modified.
But there are workarounds through which you can achieve the same result. For the work around you must remember the INSERTED and DELETED tables available in a DML trigger.
What you can do is to find out the count on these two tables .
Select @InsertedCount = count(*) from INSERTED;
Select @DeletedCount = count(*) from DELETED;
where the variables are declared as:
Declare @InsertedCount, @DeletedCount int;
Now if @InsertedCount > 0 and @DeletedCount = 0, it means that it is an insert operation.
if @InsertedCount = 0 and @DeletedCount > 0, it means that it is a delete operation.
If @InsertedCount > 0 and @DeletedCount > 0, it means that it is an update operation.
The last condition is if @InsertedCount = 0 and @DeletedCount = 0. This is not a hypothetical situation. But a real situtation. This situation can occur as a result of Update or Delete query which has selected no record to modify / delete because of the selection criteria in WHERE clause.
But there are workarounds through which you can achieve the same result. For the work around you must remember the INSERTED and DELETED tables available in a DML trigger.
What you can do is to find out the count on these two tables .
Select @InsertedCount = count(*) from INSERTED;
Select @DeletedCount = count(*) from DELETED;
where the variables are declared as:
Declare @InsertedCount, @DeletedCount int;
Now if @InsertedCount > 0 and @DeletedCount = 0, it means that it is an insert operation.
if @InsertedCount = 0 and @DeletedCount > 0, it means that it is a delete operation.
If @InsertedCount > 0 and @DeletedCount > 0, it means that it is an update operation.
The last condition is if @InsertedCount = 0 and @DeletedCount = 0. This is not a hypothetical situation. But a real situtation. This situation can occur as a result of Update or Delete query which has selected no record to modify / delete because of the selection criteria in WHERE clause.
Subscribe to:
Posts (Atom)


